Hosting DeepSeek Locally & Connecting It to a Script-Generation Pipeline (Basic)
Spin up a small DeepSeek model locally and expose a tiny /generate endpoint for script drafts.
Goal: run a local AI writer that turns short briefs into structured JSON scripts you can use immediately in your editing workflow.
What you’ll build (at a high level)
You’ll set up a local DeepSeek model and talk to it in two ways:
- Interactively — type a prompt, get ideas or outline tweaks.
- Programmatically — hit a tiny
/generateendpoint with{topic, tone, length}and get strict JSON back:{title, hook, sections[], cta}.
The aim is not a giant system; it’s a starter pipeline with predictable folders, simple logs, and guardrails (style + safety rules). Layer on extras later (thumbnail prompts, auto‑captions, etc.).
Picking a beginner‑friendly path
The simplest way to run locally is Ollama (Mac/Windows/Linux). It downloads models, runs on CPU or GPU, and exposes a small local API.
- CPU‑only: works anywhere; slower tokens/sec; fine for outlines and short scripts.
- GPU: much faster if you have enough VRAM. If VRAM is tight, use a smaller model; bigger isn’t always better if it thrashes.
Start small (e.g., deepseek-r1:1.5b). Move to :7b when you’re comfortable.
Install & run via Ollama
- Install Ollama (Mac/Win/Linux).
- Pull a model (start small; upgrade later):
ollama pull deepseek-r1:7b
- Chat interactively:
ollama run deepseek-r1:7b
Type something like: Give 10 viral hooks for budget travel in ≤ 70 characters.
Exit with Ctrl+C. Ollama also runs a background service you can stop/start from your tray/menu bar.
Where things live: models are cached by Ollama; your prompts/outputs are yours—save them in a project folder (we’ll define one below).
Prompting basics for creators
Think of prompts like a director’s note:
- Role: “You are a YouTube scriptwriter for a friendly, fact‑checked explainer channel.”
- Audience: “Teens → young adults; expand acronyms; no jargon.”
- Tone: “Upbeat, clear, slightly witty.”
- Length: “Short (60–90 sec) or Long (6–8 min).”
- Constraints: “Avoid legal/medical claims; suggest CC‑friendly b‑roll.”
- Deliverable: “Return JSON with
title, hook, sections[], ctaonly.”
Examples to request:
- Ideas: 25 video ideas in [niche], each with a one‑line hook.
- Outline: Turn topic X into a 6‑beat outline with timestamps.
- Script: Expand this outline to a 90‑second read with short sentences and on‑screen text cues.
Add a few‑shot snippet (your ideal hook + a micro‑section) to teach style.
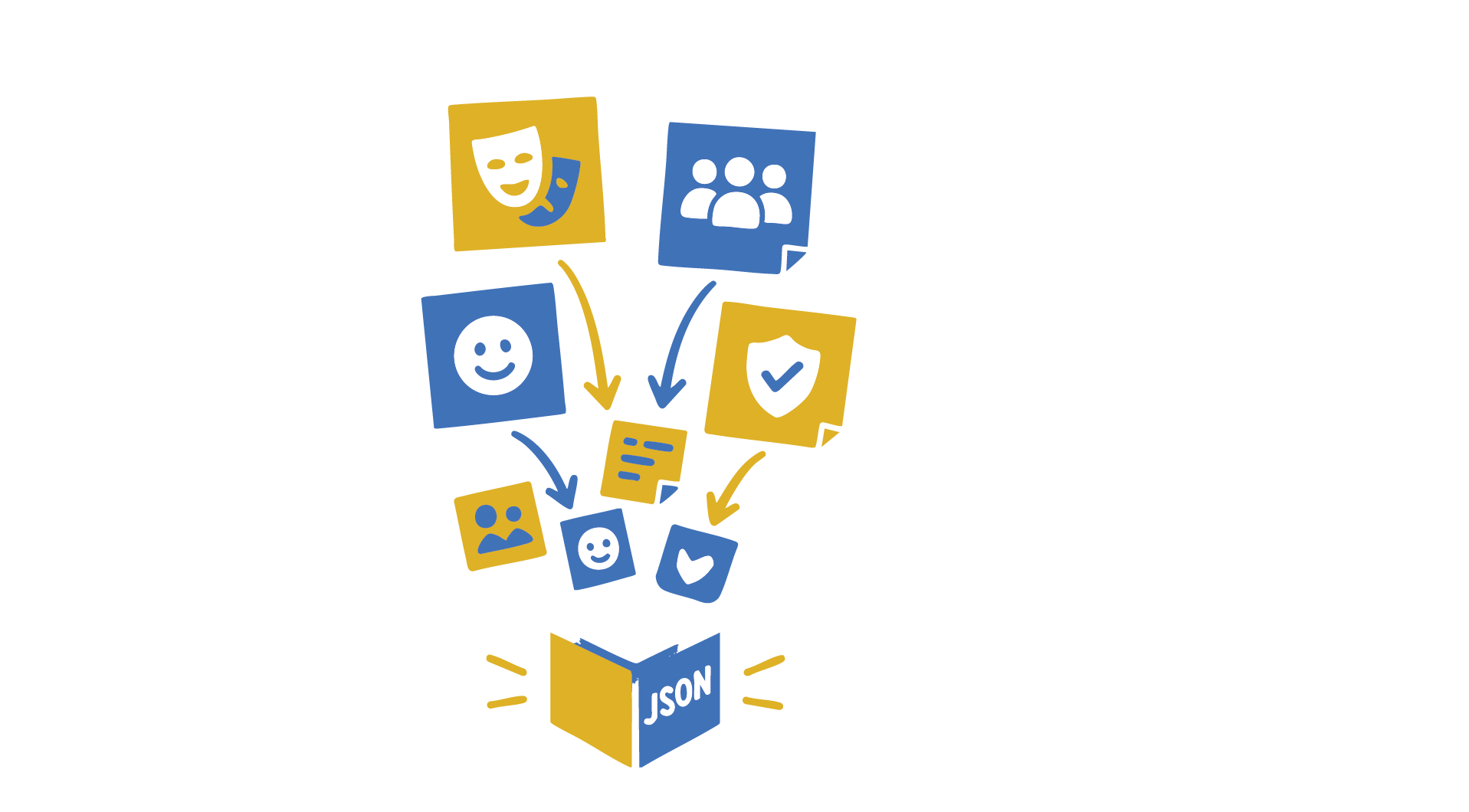
Define a simple output contract (JSON)
Unstructured text is hard to automate. Use strict JSON so tools can consume it:
{
"title": "string",
"hook": "string",
"sections": [
{ "heading": "string", "beats": ["string", "string"] }
],
"cta": "string"
}
Why this matters:
Editors can drive captions/b‑roll from sections[].beats; VO tools read the same JSON; thumbnail prompts come from title + hook.
Instruction snippet to include in prompts:
Return only valid JSON with keys title, hook, sections[], cta.
Each section has {heading, beats[]}; each beat ≤ 25 words.
Word cap: 300 (short) or 1000 (long).
Expose a tiny local API
A minimal /generate lets any app (or button) request a script. We’ll use FastAPI conceptually:
Request:
POST /generate
{
"topic": "Beginner budgeting tips",
"length": "short",
"tone": "friendly"
}
Response:
{
"title": "5 Budget Habits That Stick",
"hook": "If your wallet leaks, fix these five holes in 60 seconds.",
"sections": [
{ "heading": "The Leak Check", "beats": ["Track 3 days", "Spot impulse buys"] },
{ "heading": "The 24‑Hour Rule", "beats": ["Delay non‑essentials", "Keep a wishlist"] }
],
"cta": "Subscribe for one new habit each week."
}
Under the hood, the server builds the system prompt, adds your schema instruction, calls Ollama’s local API (http://localhost:11434) with the model name (e.g., deepseek-r1:7b), validates the JSON, and returns it. Keep a timeout and max tokens to prevent rambles.
Don’t stress about full server code yet—the shape is what matters.
A beginner pipeline that just works
Flow:
- Outline: call
/generatewithdeliverable="outline". Save to./out/YYYY‑MM‑DD/<slug>/outline.json. - Script: call again with
deliverable="script"and include the outline. Savescript.jsonand also export ascript.txt. - Image prompts: ask for 5–10 b‑roll/thumbnail prompt lines; save
prompts.txt.
Folder layout:
/out/2025-09-14/<slug>/
outline.json
script.json
script.txt
prompts.txt
request.log # the exact system+user prompts sent
response.log # raw model output before validation
Logging both prompt and raw response makes your work reproducible.
Basic guardrails:
Pre‑prompt with style & safety rules; validate JSON and lengths (≤ N beats/section); if invalid, retry with a format‑only instruction.
Caching, versioning & sanity checks
Cache by prompt hash
Concatenate: system prompt + user prompt + model + params → compute a hash, e.g., sha256. Before generating, check /cache/<hash>.json; if it exists and validates, reuse it.
Version everything
Write a model_version.txt alongside outputs with:
model=deepseek‑r1:1.5b or :7bruntime=Ollama versionprompt_pack=your system prompt bundle version (e.g., v3)params=temperature, top‑p, max tokens, num_ctx
When anything changes, bump the version and don’t reuse cache.
Schema‑on‑read
Validate every response (title present, CTA ≤ 20 words, ≤ 8 sections, ≤ 6 beats each, no empty strings). If invalid, request a format‑only fix: “Reformat to this JSON—no new content.”

A tiny evaluation loop (quality pass)
Automatic checks (fast): total words, section counts, duplicated headings, banned phrases (“as an AI”), empty beats, average sentence length, CTA length.
Manual 2‑minute review:
Hook (scroll‑stopper?) • Clarity (no jargon?) • Flow (beats build?) • Specifics (at least one concrete example?) • Tone (on brand?) • Safety (no legal/medical claims). Score 0–2 each. If weak, send a targeted revision prompt (“Tighten hook; add 2 concrete examples in sections 2–3; keep JSON schema.”).
Example prompts (copy‑paste)
System (role & rules):
You are a YouTube scriptwriter for a friendly, fact-checked explainer channel.
Audience: teens to young adults. Expand acronyms. Avoid jargon.
Tone: upbeat, clear, slightly witty. Avoid legal/medical claims.
Return ONLY valid JSON with keys: title, hook, sections[], cta.
Each section has {heading, beats[]} where each beat ≤ 25 words.
For "short": max total words 300. For "long": max 1000.
User (short script):
topic: "Why airplanes leave white trails"
length: "short"
deliverable: "script"
style_notes: "start with a surprising hook; add 2 concrete examples"
User (outline only):
topic: "5 ways to read faster without losing comprehension"
length: "long"
deliverable: "outline"
Performance expectations & troubleshooting
Low VRAM / OOM: use 1.5b or a lower‑memory quantization; reduce num_ctx and max tokens; close GPU‑hungry apps.
Cold starts: first call loads weights—expect a pause; keep a warm ping.
Short/cut outputs: bump max tokens; ensure your cap is by beats not just words.
Off‑brief/rambling: lower temperature; strengthen system prompt; add a few‑shot.
When to size up: if ideas feel shallow and structure brittle—and speed is acceptable—try :7b.
Optional: File naming & slugs
Name output folders by date + slug: 2025-09-14/why-airplanes-leave-white-trails/. Generate slugs by lowercasing, replacing spaces with dashes, stripping punctuation. This keeps edits, captions, and thumbnails in sync.
Optional: Simple GUI button (bonus idea)
Even a tiny HTML page with a topic field and a “Generate” button that POSTs to /generate makes this feel like an app. Save results into out/… and display a quick preview of title + hook + first 2 beats.

Safety, privacy & ethics
- Keep your content local unless you choose to sync.
- Don’t impersonate; be clear when outputs are AI‑assisted.
- Store prompts/outputs with version notes so collaborators can audit changes.
- If you include third‑party facts or quotes, cite and verify before publishing.